
从 2017 年的第一波 dApp 开始,到如今各式各样基于不同区块链的金融、游戏与社交 dApp 百花齐放,当我们谈论去中心化的链上应用时,是否曾思考过这些 dApp 在交互中所采纳的各类数据的源头?
2024 年,热点聚焦于 AI 与 Web3,在人工智能的世界里,数据就像是其成长与进化的生命源泉。正如植物依赖阳光和水分才能茁壮成长,AI 系统同样依赖海量的数据来不断「学习」和「思考」。没有数据,AI 的算法再精妙也不过是空中楼阁,无法发挥其应有的智能与效能。
本文从区块链数据可访问性(Data Accessibility)的角度,深入分析了行业发展过程中区块链数据索引的演变,并对比了老牌数据索引协议 The Graph 与新兴的区块链数据服务协议 Chainbase 和 Space and Time,特别探讨了这两个结合 AI 技术的新晋协议在数据服务与产品架构特色的异同。
2.1 数据源头:区块链节点
从一开始了解「区块链是什么」时,我们就常看到这样一句话:区块链是去中心化的记账本。区块链节点是整个区块链网络的基础,承担着记录、存储和传播链上所有交易数据的责任。每个节点都拥有一份完整的区块链数据副本,确保网络的去中心化特性得以维持。然而,对于普通用户来说,自建和维护一个区块链节点并非易事。这不仅需要专业的技术能力,还伴随着高昂的硬件和带宽成本。同时,普通的节点查询能力也有限,无法以开发人员需要的格式查询数据。因此,尽管理论上每个人都可以运行自己的节点,但实际操作中,用户通常更倾向于依赖第三方服务。
为了解决这一问题,RPC(远程过程调用)节点提供商应运而生。这些提供商负责节点的成本和管理,并通过 RPC 端点提供数据。使得用户可以无需自建节点,便可轻松访问区块链数据。公共 RPC 端点是免费的,但有速率限制,可能会对 dApp 的用户体验产生负面影响。私有 RPC 端点通过减少拥塞提供更好的性能,但即使是简单的数据检索也需要大量的来回通信。这使得它们请求繁重,对于复杂的数据查询效率低下。此外,私有 RPC 端点通常难以扩展,并且缺乏跨不同网络的兼容性。但节点提供商标准化的 API 接口给予了用户访问链上的数据更低的门槛,为后续的数据解析和应用打下了基础。
2.2 数据解析:从原型数据到可用数据
从区块链节点获取的数据往往是经过加密和编码处理的原始数据。这些数据虽然保留了区块链的完整性和安全性,但其复杂性也增加了数据解析的难度。对于普通用户或者开发者来说,直接处理这些原型数据需要大量的技术知识和计算资源。
数据解析的过程在这一背景下显得尤为重要。通过将复杂的原型数据进行解析,转换为更易理解和操作的格式,用户可以更直观地理解和利用这些数据。数据解析的成功与否直接决定了区块链数据应用的效率和效果,是整个数据索引流程中的关键一步。
2.3 数据索引器的演进
随着区块链数据量的增加,数据索引器的需求也日益增加。索引器在组织链上数据并将其发送到数据库以便于查询方面起着至关重要的作用。索引器的工作原理是索引区块链数据并通过类似于 SQL 的查询语言(GraphQL 等 API)使其随时可用。通过提供查询数据的统一界面,索引器允许开发人员使用标准化查询语言快速准确地检索所需的信息,从而大大简化了流程。
不同类型的索引器通过各种方式优化数据检索:
目前,以太坊档案节点(Archive Node)在 Geth 客户端中的存档模式占用了约 13.5 TB 的存储空间,而在 Erigon 客户端下,存档需求约为 3 TB。随着区块链的不断增长,档案节点的数据存储量也会随之增加。面对如此庞大的数据量,主流索引器协议不仅支持多链索引,还针对不同应用的数据需求,定制了数据解析框架。例如,The Graph 的「子图」(Subgraph)框架就是一个典型案例。
索引器的出现大大提升了数据的索引和查询效率。与传统的 RPC 端点相比,索引器可以高效地索引大量数据,并支持高速查询。这些索引器允许用户执行复杂的查询,轻松过滤数据,并在提取后进行分析。此外,一些索引器还支持聚合来自多个区块链的数据源,避免在多链 dApp 中需要部署多个 API 的问题。通过在多个节点上分布式运行,索引器不仅提供了更强的安全性和性能,也减少了集中式 RPC 提供商可能带来的中断和停机风险。
相比之下,索引器通过预先定义的查询语言,使得用户可以在无需处理底层复杂数据的情况下,直接获取所需信息。这种机制显著提高了数据检索的效率和可靠性,是区块链数据访问的重要创新。
2.4 全链数据库:向流优先对齐
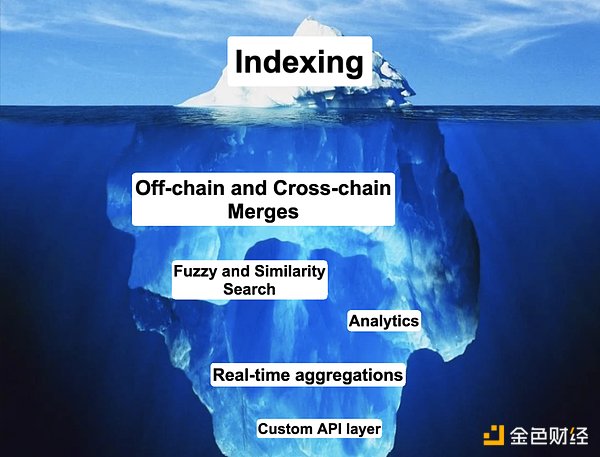
使用索引节点查询数据通常意味着 API 成为消化链上数据唯一门户。然而,当一个项目进入扩展阶段时,往往需要更灵活的数据源, 而这是标准化的 API 无法提供的。随着应用需求的复杂化,初级数据索引器与其标准化的索引格式逐渐难以满足越来越多样化的查询需求,例如搜索、跨链访问或链下数据映射。

在现代数据管道架构中,「流优先」方法已经成为解决传统批处理局限性的一种方案,能够实现实时的数据摄取、处理和分析。这种范式的转变使得组织能够对传入数据立即作出响应,从而几乎即时地得出洞察并做出决策。类似地,区块链数据服务提供商的发展也正朝着构建区块链数据流的方向前进,传统索引器服务商均陆续推出了以数据流方式获取实时区块链数据的产品,例如 The Graph 的 Substreams,Goldsky 的 Mirror,也有如 Chainbase 和 SubSquid 这样根据区块链生成数据流的实时数据湖。
这些服务旨在解决对区块链交易进行实时解析和提供更全面查询能力的需求。正如「流优先」架构通过降低延迟和增强响应能力,革新了传统数据管道中的数据处理和消费方式一样,这些区块链数据流服务商也希望通过更先进且成熟的数据源,支持更多应用程序的发展并辅助链上数据分析。
通过现代数据管道的视角重新定义链上数据的挑战,我们得以从全新的角度看待链上数据的管理、存储和提供的全部潜力。当我们开始将子图和以太坊 ETL 等索引器视为数据管道中的数据流而非最终输出时,便可以设想一个能够为任何业务用例量身定制高性能数据集的可能世界。
3.1 The Graph
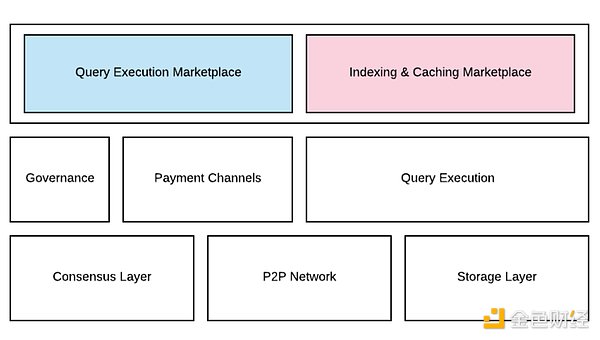
The Graph 网络通过一个去中心化的节点网络来实现多链数据索引和查询服务,促进开发者便捷地索引区块链数据并构建去中心化应用。其主要的产品模式为数据查询执行市场和数据索引缓存的市场,这两个市场本质都是服务于用户的产品查询需求,其中数据查询执行市场具体指消费者为所需的数据选择合适的提供数据的索引节点付费,数据索引缓存的市场则是索引节点依据子图的历史索引热度、收取的查询费、链上策展人对子图输出的需求调动资源分配的市场。
子图(Subgraphs)是 The Graph 网络中的基础数据结构。它们定义了如何从区块链中提取并转换数据为可查询的格式(例如 GraphQL 模式)。任何人都可以创建子图,且多个应用可以重复使用这些子图,这提升了数据可复用性和使用效率。

The Graph 产品结构 (Source: The Graph Whitepaper)
The Graph 网络由四个关键角色构成:索引器、策展人、委托人和开发者,他们共同为 web3 应用提供数据支持。以下是他们各自的职责:

目前 The Graph 已经转向全面的去中心化子图托管服务,不同的参与方之间有流通的经济激励确保系统运转:
事实上,The Graph 的产品也在 AI 浪潮中迅速发展。作为 The Graph 生态系统的核心开发团队之一,Semiotic Labs 一直致力于利用 AI 技术优化索引定价和用户查询体验。当前,Semiotic Labs 开发的 AutoAgora、Allocation Optimizer 和 AgentC 工具分别在多个方面提升了生态系统的性能。
这些工具的应用使得 The Graph 结合 AI 辅助进一步提升了系统的智能化和用户友好度。
3.2 Chainbase
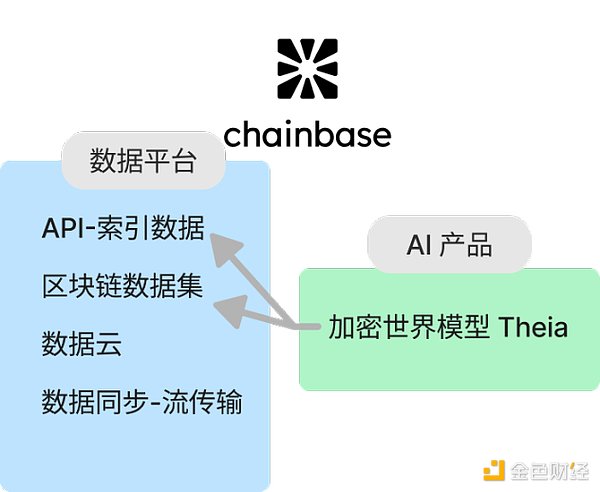
Chainbase 是一个全链数据网络,将所有区块链数据整合到一个平台,方便开发者更轻松地构建和维护应用程序。它的独特功能包括:

这些功能使 Chainbase 在区块链索引协议中脱颖而出,尤其注重实时数据的可访问性、创新的数据格式,以及通过链上和链下数据的结合,创建更智能的模型以提升洞察力。
Chainbase 的 AI 模型 Theia 是其区别于其他数据服务协议的关键亮点。Theia 基于 NVIDIA 开发的 DORA 模型,结合链上和链下数据以及时空活动,学习并分析加密模式,并通过因果推理做出响应,从而深入挖掘链上数据的潜在价值和规律,为用户提供更加智能化的数据服务。
AI 赋能的数据服务使 Chainbase 不再仅仅是一个区块链数据服务平台,而成为一个更具竞争力的智能化数据服务商。通过强大的数据资源和 AI 的主动分析,Chainbase 能够提供更广泛的数据洞察,并优化用户的数据处理过程。
3.3 Space and Time
Space and Time (SxT) 意在打造可验证的计算层,在去中心化数据仓库上扩展零知识证明,从而为智能合约、大语言模型和企业提供可信的数据处理。目前 Space and Time 已获得 2000 万美元最新一轮的 A 轮融资,由 Framework Ventures、Lightspeed Faction、Arrington Capital 和 Hivemind Capital 领投。
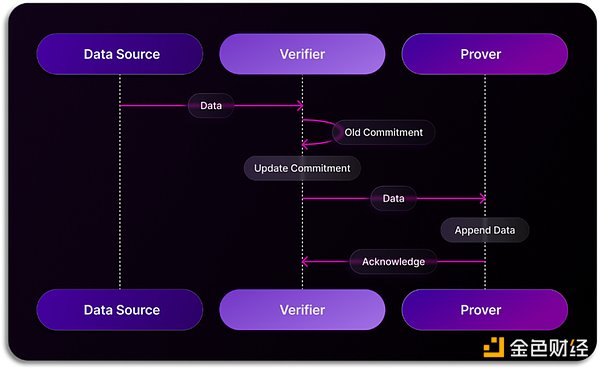
在数据索引和验证领域,Space and Time 引入了一种全新的技术路径——Proof of SQL。这是 Space and Time 开发的一种创新零知识证明(ZKP)技术,确保在去中心化数据仓库上执行的 SQL 查询是防篡改的和可验证的。当运行查询时,Proof of SQL 会生成一个加密证明,验证查询结果的完整性和准确性。这个证明附加在查询结果上,使任何验证者(如智能合约等)都可以独立确认数据在处理过程中未被篡改。传统的区块链网络通常依赖共识机制来验证数据的真实性,而 Space and Time 的 Proof of SQL 实现了一种更为高效的数据验证方式。具体来说,在 Space and Time 的系统中,一个节点负责数据的获取,而其他节点则通过 zk 技术验证该数据的真实性。这种方式改变了共识机制下多个节点重复索引相同数据的到最终达成共识获取数据的资源损耗,提升了系统的整体性能。随着这项技术的成熟,它为着重数据可靠性的一系列传统行业使用区块链上数据构造产品打造了落脚石。

同时,SxT 一直与微软 AI 联合创新实验室密切合作,加速研发生成式 AI 工具,方便用户更轻松地通过自然语言处理区块链数据。目前在 Space and Time Studio 中,用户可以体验输入自然语言查询,而 AI 会自动将其转换为 SQL 并代表用户执行查询语句呈现用户需要的最终结果。
3.4 差异对比

综上所述,区块链数据索引技术从最初的节点数据源头,经过数据解析和索引器的发展,最终演进到 AI 赋能的全链数据服务,经历了一个逐步完善的过程。这些技术的不断演进,不仅提高了数据访问的效率和准确性,还为用户带来了前所未有的智能化体验。
展望未来,随着 AI 技术和零知识证明等新技术的不断发展,区块链数据服务将进一步智能化和安全化。我们有理由相信,区块链数据服务将在未来作为基础设施继续发挥重要作用,为行业的进步和创新提供有力支持。



鸿蒙5“自救”大戏:左手抖音,右手政务,能逃离安卓“换皮”魔咒?
2025-04-02
幣圈血祭:23歲青年自殺引爆Meme幣狂潮,誰是嗜血的鬣狗?
2025-04-01



雪域苍狼
回复这是一篇很好的文章,深入分析了区块链数据索引技术的发展和未来趋势,特别是提到了AI在数据服务中的作用,让我对这个领域有了更深的了解。
墨韵天涯
回复這篇文章讓我更了解了鏈上數據的演進,從最初的節點到現在的 AI 賦能,真的非常有趣!特別是 AI 應用部分,Chainbase 和 Space and Time 的做法都蠻值得關注,期待未來發展!
ThunderPhoenix
回复这篇文章非常详细地阐述了区块链数据索引技术的演变过程,从节点数据源头到 AI 赋能的全链数据服务,并对比分析了 The Graph, Chainbase 和 Space and Time 三种不同数据索引协议的优势和劣势,让我对 Web3 数据索引领域有了更清晰的认识。
BlazeHunter
回复非常详细地介绍了区块链数据索引的演进过程,特别是 The Graph, Chainbase 和 Space and Time 三者的对比,对于理解 Web3 数据服务的未来趋势很有帮助。
青春记忆
回复这篇文章非常全面地阐述了区块链数据索引技术的发展历程,从节点数据到全链数据库,并深入对比了 The Graph、Chainbase 和 Space and Time 三种主流协议。文章还分析了 AI 技术在数据索引领域的应用,以及未来发展趋势。这篇文章为我理解区块链数据索引提供了宝贵的参考,并让我对未来 Web3 数据服务的发展充满期待。
幽影轻歌
回复非常详细地介绍了区块链数据索引技术的发展历程,从节点到全链数据库,并对比了The Graph、Chainbase、Space and Time这三种主流协议的特点。尤其是对AI技术在区块链数据服务中的应用进行了深入的探讨,让我对这个领域的未来发展充满了期待。